Instructions to Generate and Load a Dataset in MultiStream
MultiStream supports a JSON file containing time series organized in a hierarchy structure. We provide a script that helps you generate this file. Follow the instructions below to create a compatible dataset and load it into MultiStream.
Preparing your data
To start, you need two input files:
-
CSV File: Time Series Data
This file must contain the following structure: (example)-
First column: it must be named date and formatted using ISO-8601, either as YYYY-MM-DD or YYYY-MM-DD HH:mm:ssZ
- The Z suffix is required if using UTC
- Suported time granularities: minutes, hours, days, weeks, months and years
- Examples: 2000-01-01 or 2016-05-28 19:50:00
- Other columns: time series category names. These must be strings identifying each individual time series
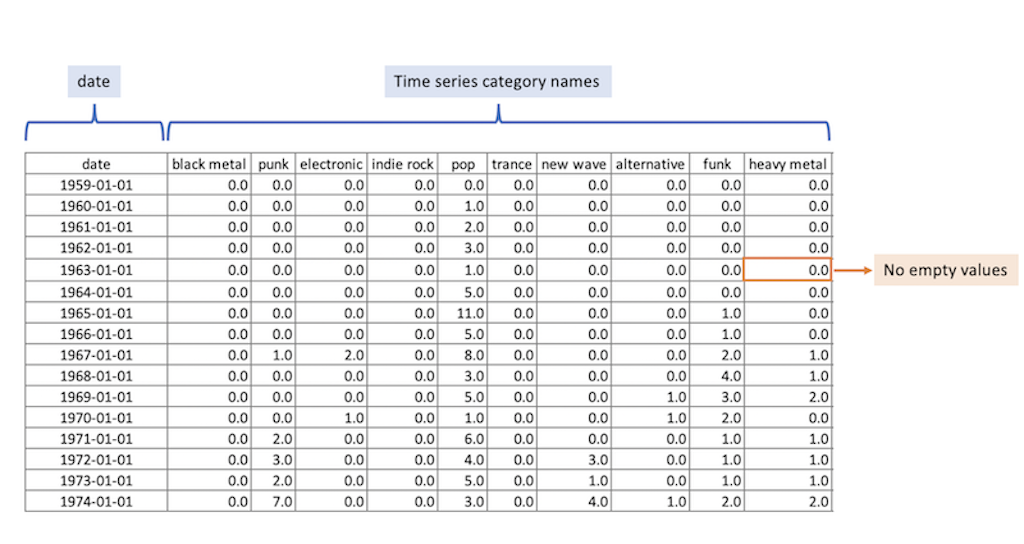
-
First column: it must be named date and formatted using ISO-8601, either as YYYY-MM-DD or YYYY-MM-DD HH:mm:ssZ
-
JSON File: Hierarchical Structure
This file should define the hierarchy of your categories (example)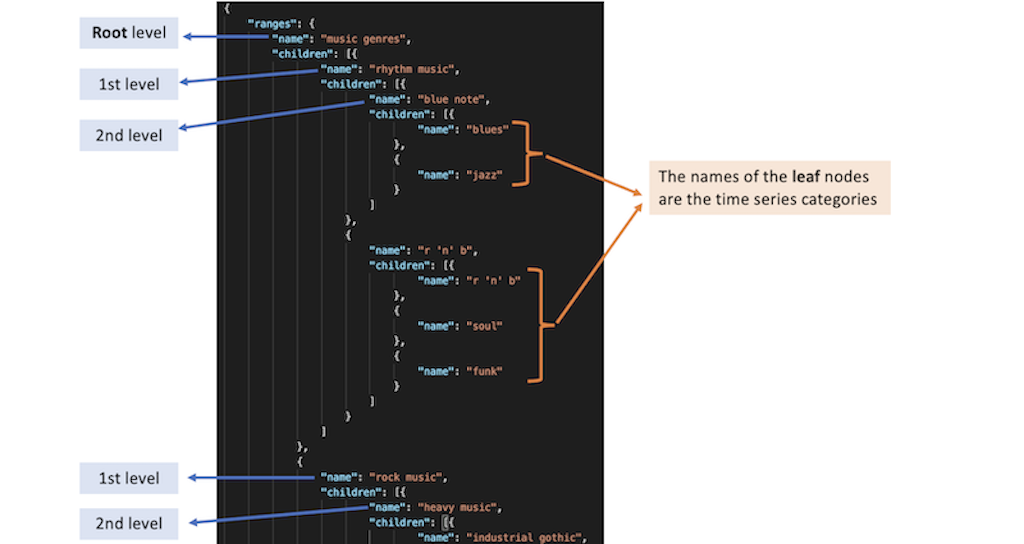
Generating a supported file
We provide a preprocessing script that transforms your CSV and JSON file into a format that MultiStream can load.
Prerequisites
- Node.js version 14 or later
- Download the required script and dependencies: generate_supported_file.zip
- Open your terminal (Linux/macOS) or command prompt (Windows), navigate to the downloaded folder, and run: npm i
Run the script
Use the command line to execute preprocessing.js with the following arguments:| Argument | Description |
|---|---|
--raw (required) |
Path to the CSV file with the raw time series data |
--hierarchy (required) |
Path to the JSON file containing the hierarchy |
--output (required) |
Path to save the output JSON file |
--granularity (required) |
Time unit used in the series Allowed values: minutes, hours, days, weeks, months, years |
--step (required) |
Step size between time points (usually 1) |
--datatype (optional) |
Description of the time series data (e.g., "number of bands") |
You can run the script using this command:
node preprocessing.js --raw=input/data.csv --hierarchy=input/hierarchy.json --output=output.json --granularity=years --step=1 --datatype="number of bands"
This will generate a file named output.json, which can be loaded by MultiStream.
Loading the file in MultiStream
Go to the MultiStream web application and upload the generated file (e.g., output.json).Tips & requirements
CSV File: Time Series Data
- Use clear, unique, and non-empty column names.
- The first column must be named
dateand follow the ISO-8601 format (e.g.,YYYY-MM-DDorYYYY-MM-DD HH:mm:ssZ). - Avoid missing or null values in any column.
JSON File: Hierarchical Structure
- Define a clear hierarchical structure for the time series categories.
- Ensure every category in the hierarchy matches a column name in the CSV (excluding
date). - Use valid JSON syntax and ensure correct nesting of hierarchy nodes.
If you have any questions or run into issues, feel free to contact us