Our project !
Abstract
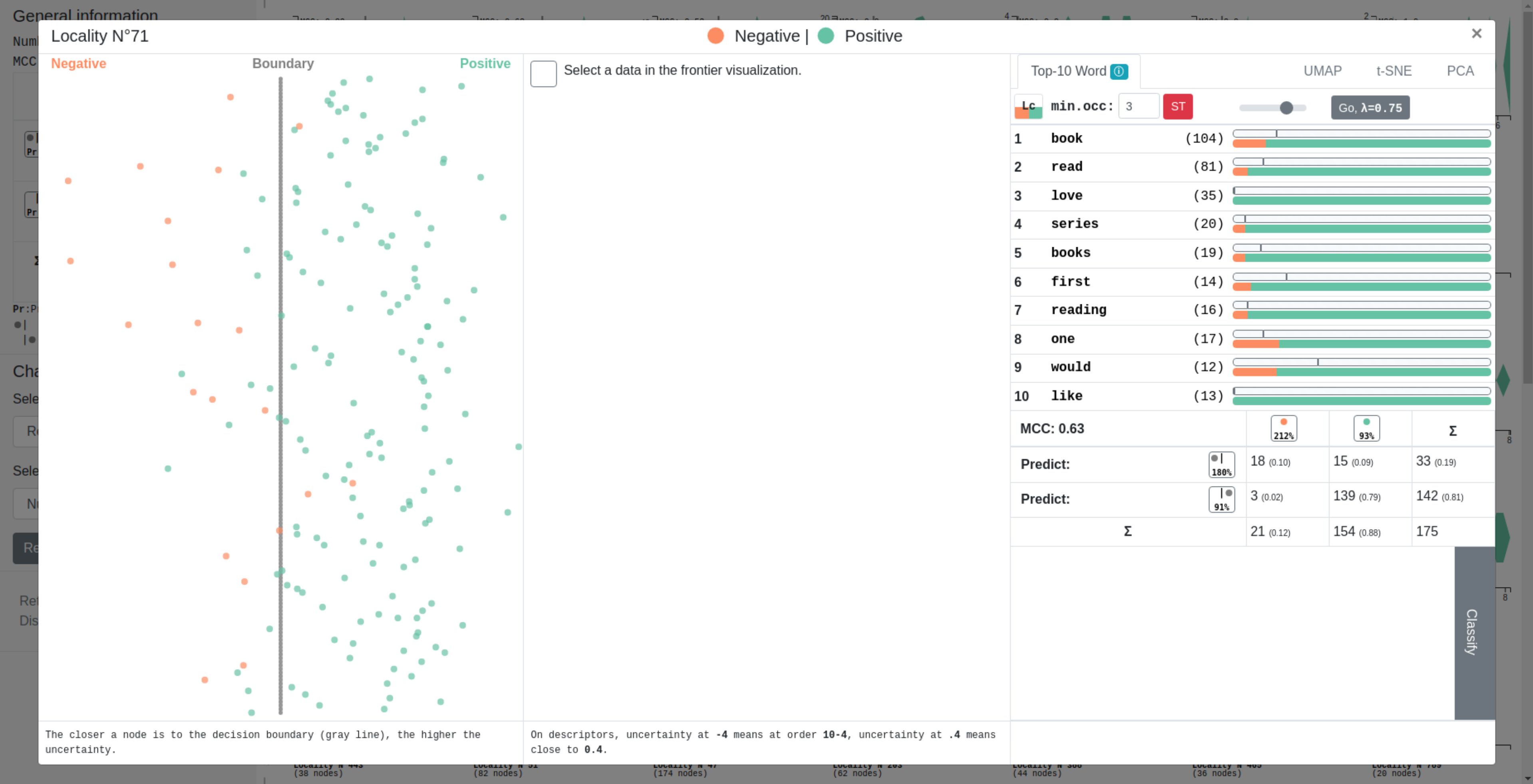
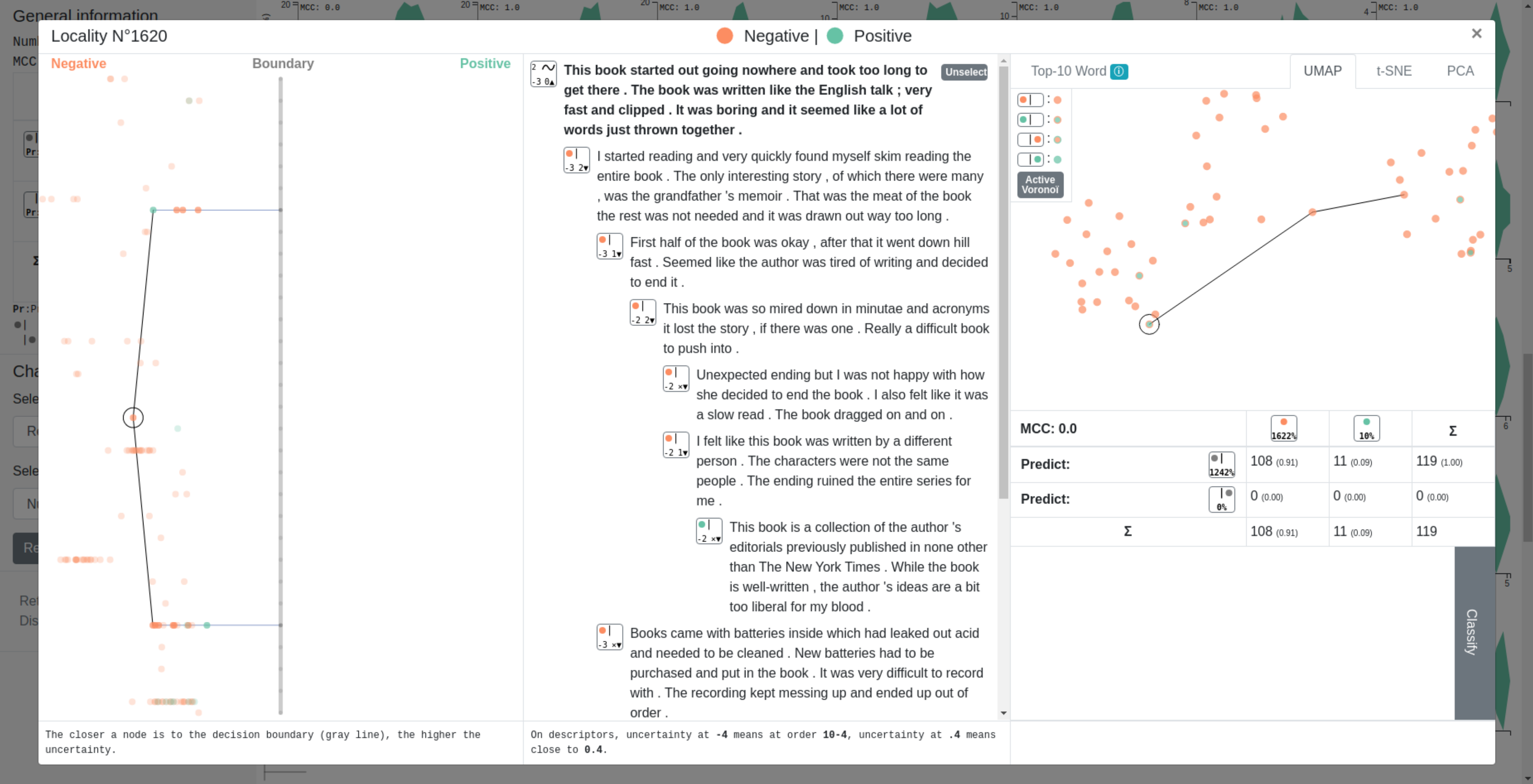
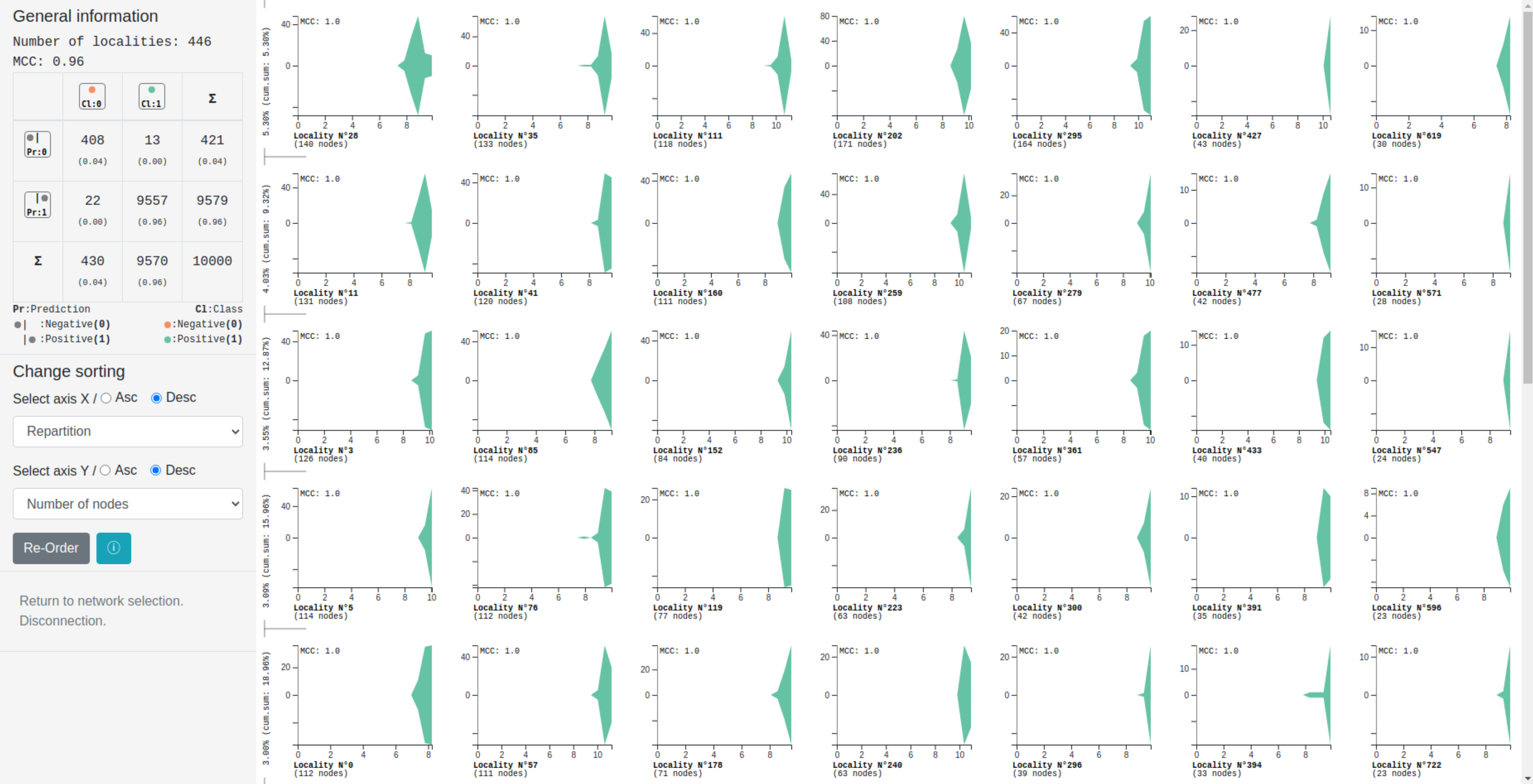
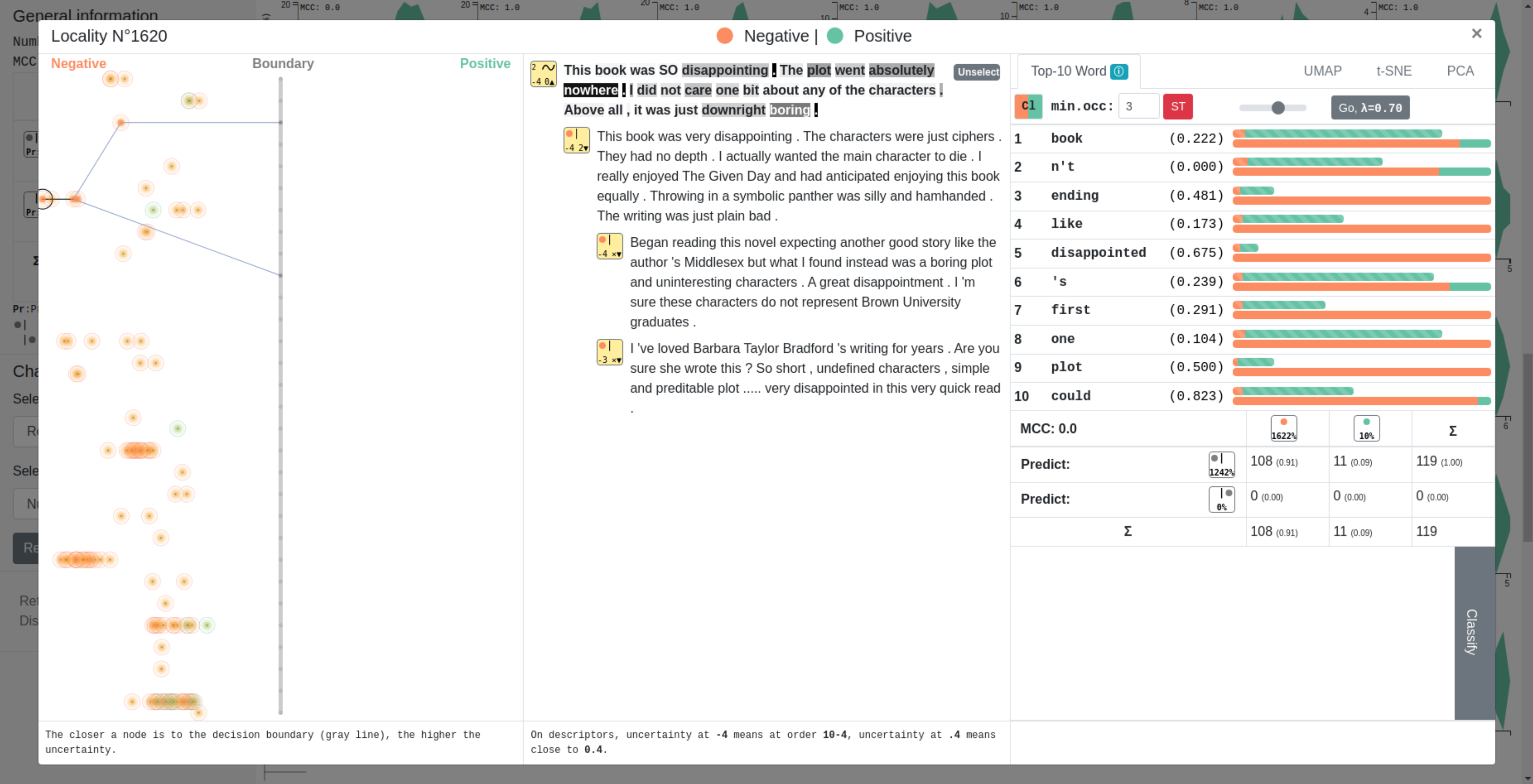
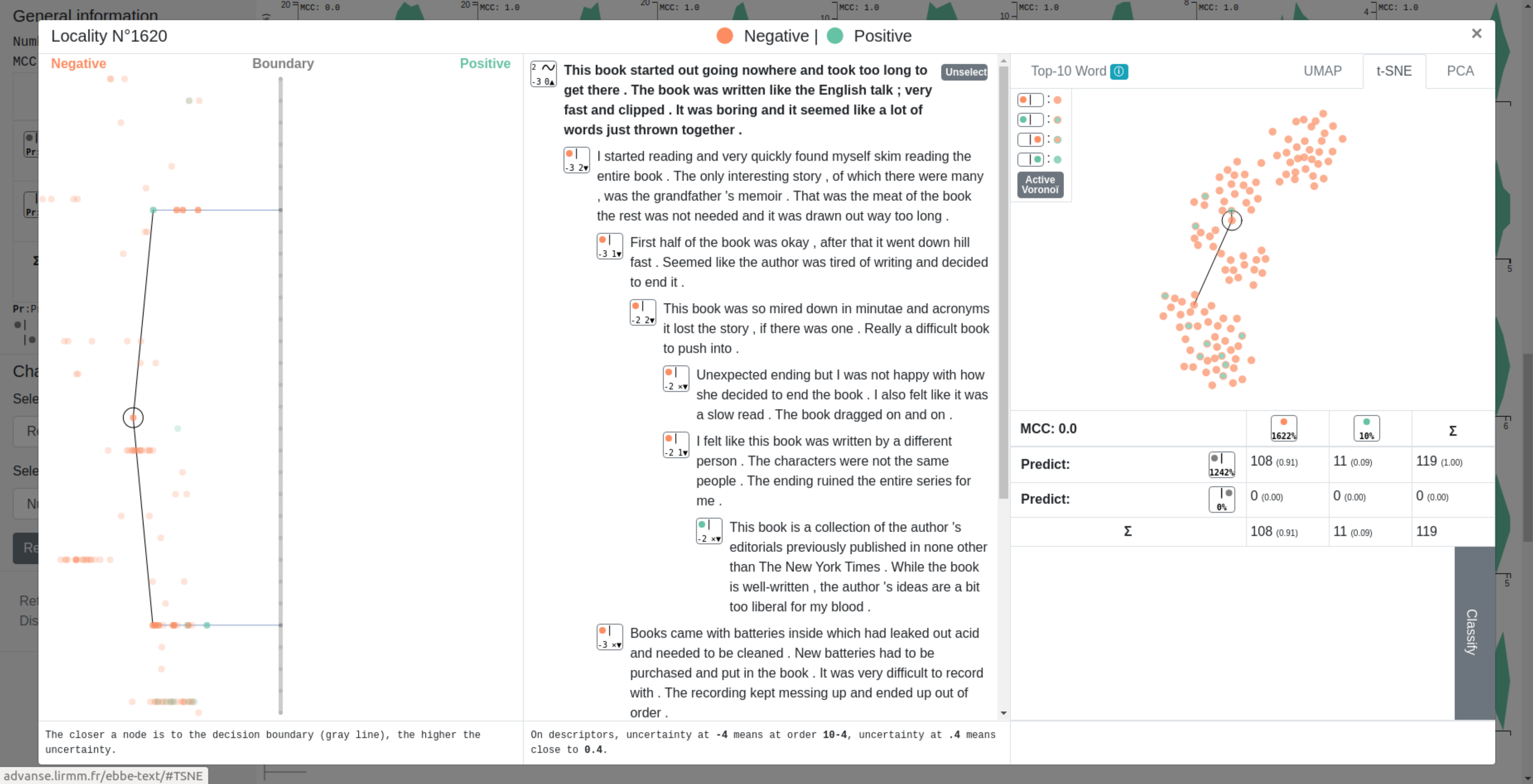
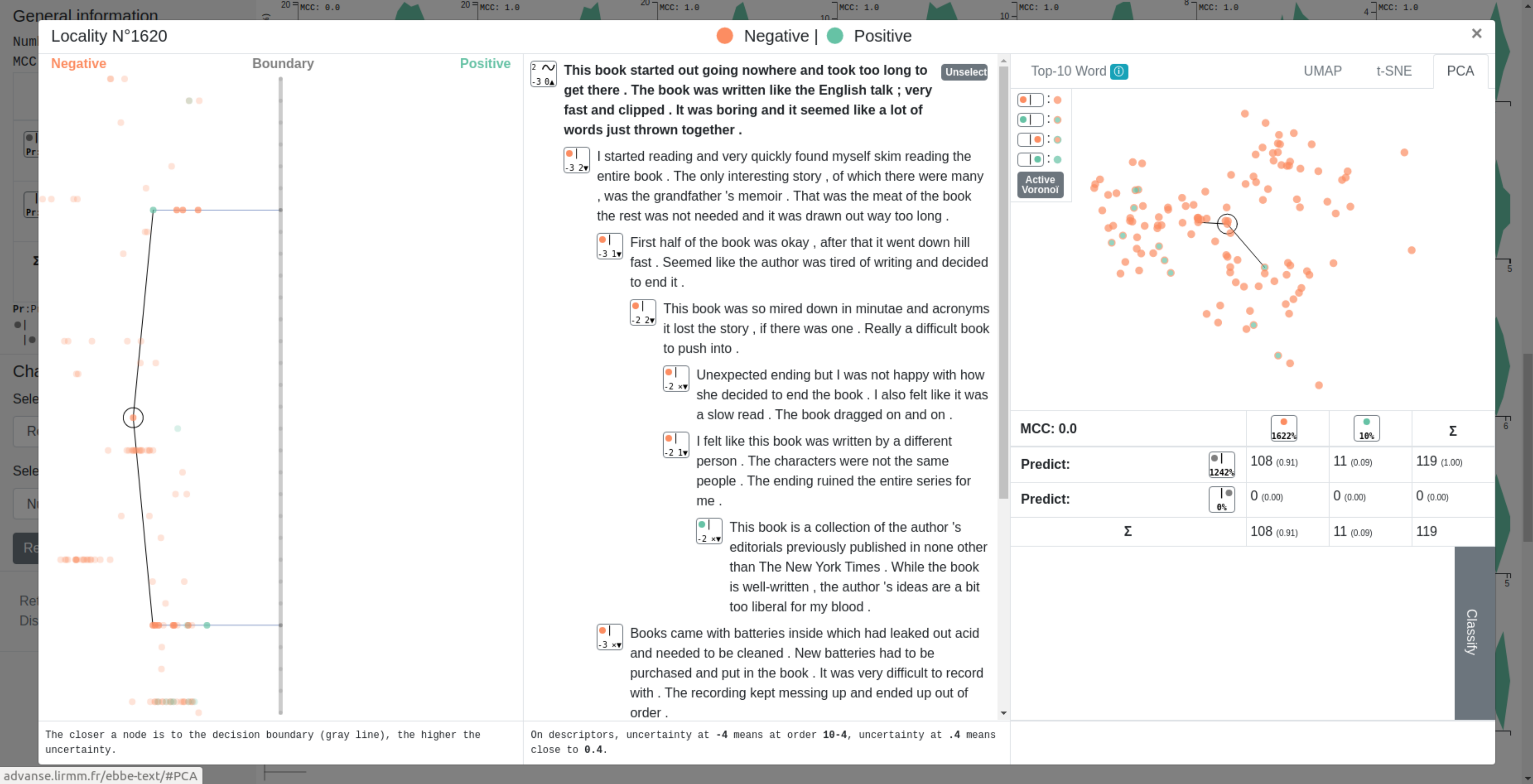
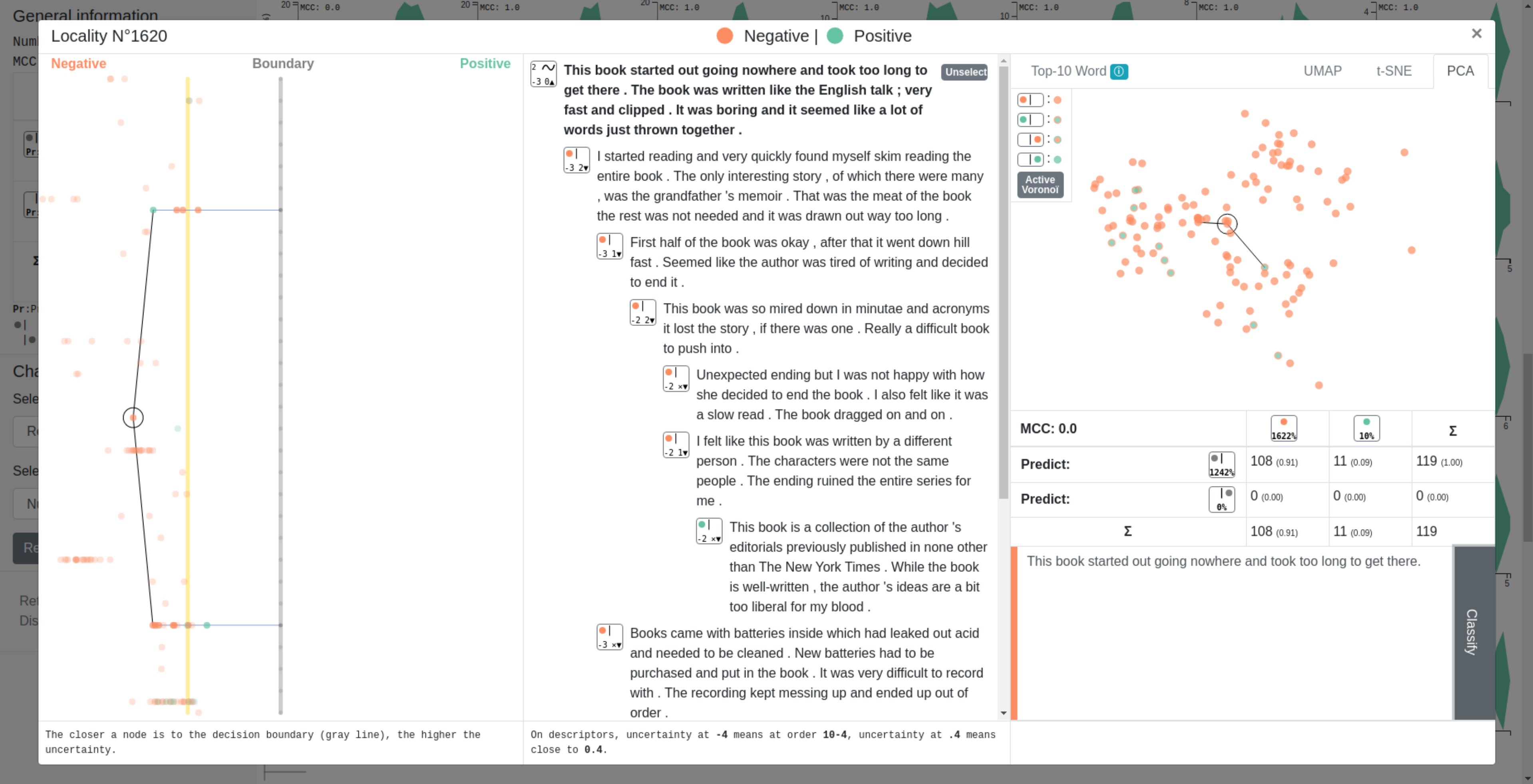
In text classification, many recent works deal with the interpretation of neural networks by producing explanations of predictions. The original approach presented in this paper consists in visualizing the decision boundary and the positioning of our data with respect to it, thus offering a new approach to explanation.
Our method first computes a sentence representation space and then exploits its linear structure in order to visualize the distribution and clustering of data around the decision boundary. The main contribution of our method is the decision boundary visualization process, allowing to explore the distance to the decision boundary (and thus the certainty of a network in its predictions) but also the paths leading to it or the proximity between sentences.
Click on images :